Data Base Relazionale Access.
By Fausto Marinsalta
3.1 Banche dati e query languages.
Le banche dati
gerarchiche o relazionali ed i linguaggi di tipo procedurale sono gli strumenti
per la realizzazione dei Sistemi Informativi a livello operativo, caratterizzati
da grandi volumi di dati e da operazioni ripetitive.
Per i livelli
direzionale e strategico sono necessari strumenti più flessibili, in grado di
ricavare dalle banche dati le informazioni in risposta a problemi estemporanei,
in breve tempo e senza il supporto di personale con elevate competenze
informatiche.
Per la
registrazione dei dati la struttura del data base relazionale, grazie alla sua
flessibilità di accesso, costituisce la base indispensabile. Tale banca dati
può essere generata in modo specifico per rispondere ad esigenze del singolo
utente o di un gruppo di utenti (banca dati settoriale), o può essere ricavata
dalle banche dati operative (banche dati aziendali), con processi che
consentono di estrarre esclusivamente i dati interessanti per i processi
elaborativi previsti. In ogni caso, alla base della costituzione di questi data
base è necessario un processo di progettazione, in grado di definire i dati
necessari e la loro struttura nell'ambito della banca dati.
Per quanto
riguarda i processi elaborativi, sono necessari linguaggi particolari,
orientati all'estrazione dei dati, ad elaborazioni semplici ed alla
presentazione dei risultati in formato di report o di grafici. Tali linguaggi
(query languages) devono essere di facile apprendimento, in quanto ne è
previsto l'utilizzo diretto da parte degli utenti finali, ai quali non vengono
richieste competenze informatiche particolari.
Per questi livelli
del Sistema Informativo, sono perciò a carico dell'utente finale sia la
progettazione e realizzazione delle banche dati, sia l'automazione dei processi
di estrazione e presentazione delle informazioni.
3.2 La progettazione.
Il processo di
progettazione è alla base della realizzazione di un data base efficiente, in
termini di velocità di risposta, ed efficace, ossia in grado di fornire le
informazioni richieste.
Le fasi di
progettazione di un data base relazionale possono essere così sintetizzate:
§
Definizione degli obiettivi del data base,
in base ai quali vengono individuati i dati che devono essere memorizzati nel
data base.
§
Definizione delle tabelle, ossia
suddivisione dei dati per "argomenti", che costituiranno le tabelle
del data base.
§
Definizione dei campi, ossia dei singoli
dati da inserire nelle tabelle e delle relative caratteristiche (tipologia,
dimensioni, metodo di rappresentazione, …).
§
Definizione delle relazioni, ossia dei
legami tra le tabelle, legami che consentono la costruzione di record logici
mediante record fisici diversi.
§
Verifica della struttura ed eventuali
correzioni.
La progettazione
ha come obiettivo la definizione dell'architettura generale del data base, che
dovrà rimanere inalterata nel tempo. Nuovi dati potranno essere aggiunti anche
successivamente, ampliando la struttura delle tabelle o aggiungendo nuove
tabelle. Perché questo non comporti una revisione di quanto già realizzato, è
indispensabile che rimanga invariata l'architettura generale.
3.3 Strumenti di supporto.
Nel caso di
software di gestione del data base orientato verso la realizzazione di banche
dati settoriali, e quindi destinato direttamente agli utenti finali, è
necessario che siano resi disponibili strumenti di facile utilizzo, per
realizzare tutte le fasi di definizione della struttura, dell'inserimento dei
dati, dell'estrazione di informazioni e della presentazione dei risultati.
In figura è
riportata la mappa delle macrofunzioni disponibili in Access, il data base
relazionale più diffuso per l'informatica individuale.
Risultano disponibili le seguenti funzioni:
§
Tabelle: per la generazione della struttura,
la registrazione dei dati, la loro visualizzazione e correzione.
§
Query: per l'estrazione ed eventuale
modifica di informazioni con interrogazioni di tipo condizionato.
§
Maschere: per la realizzazione di intefacce
a tutto schermo, per la visualizzazione o l'introduzione di dati.
§
Report: per la produzione di tabulati a
stampa.
§
Macro: per l'automazione di operazioni
ripetitive, che prevedono l'utilizzo in sequenza di più funzioni base.
§
Moduli: per la realizzazione di funzioni nel
linguaggio Access Basic.
3.4 Realizzazione di una tabella.
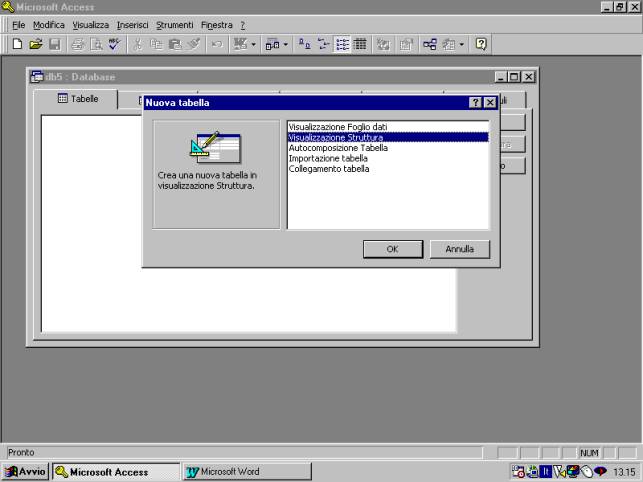
Per la creazione di una nuova tabella è necessario innanzitutto
definirne la struttura, ossia definire i campi che la compongono ed i loro
attributi.
Per ogni dato
occorre definire il nome del campo, il tipo dei dati, ed una serie di
caratteristiche, in parte comuni ed in parte collegate al tipo dei dati.
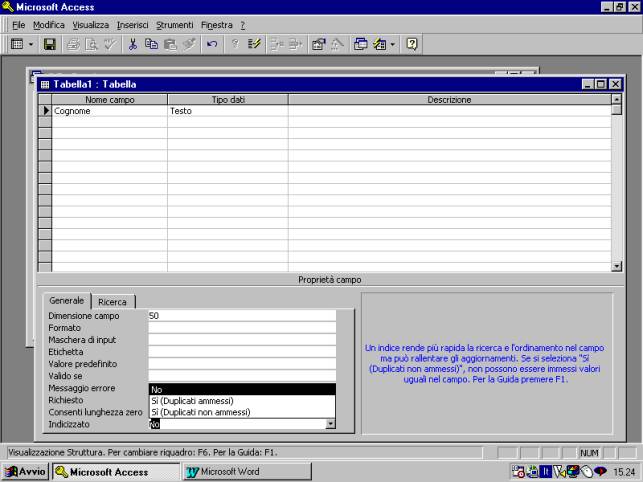
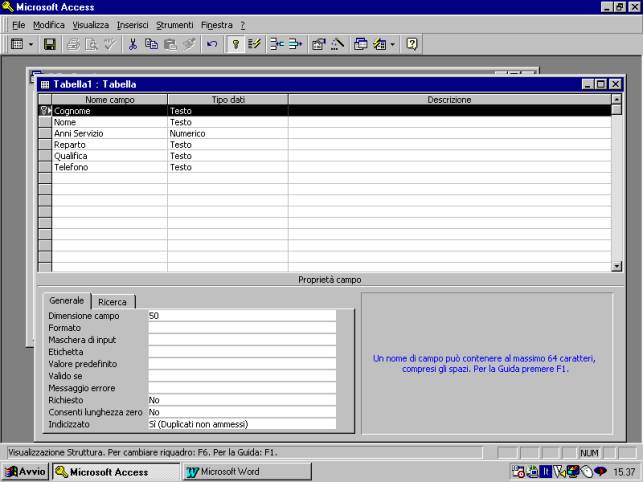
Nell'esempio in
figura viene inserito il campo Cognome, di tipo testo, con dimensione di 50
caratteri. I tipi dati disponibili sono visibili mediante una tendina che si
può aprire nella cella testo, come evidenziato nella figura che segue.
Sono
caratteristica del tipo del dato attributi quali:
§
La dimensione, che permette di definire
l'ampiezza del campo.
§
Il formato, che permette di visualizzare nel
modo desiderato valori numerici, date, valute, …
§
La presenza di cifre decimali, per i campi
numerici.
Altri attributi
sono validi per tutti i tipi:
§
La "maschera di input" permette di
visualizzare dei caratteri di definizione del formato di un campo, per
garantire che i dati immessi rispettino tale formato.
§
L' "etichetta" permette di
assegnare un nome diverso al campo nelle maschere di input ed output.
§
Il "valore predefinito" fa sì che
venga inserito automaticamente tale valore in tutti i nuovi record, per cui è
necessario immettere il valore corretto solo nel caso sia diverso dal valore
predefinito.
§
"Valido se …" consente di
immettere degli intervalli di validità per i dati immessi.
§
"Messaggio di errore" è
l'avvertimento che compare nel caso non sia rispettato l'intervallo di
validità.
§
"Consenti lunghezza zero" permette
di avere stringhe senza caratteri nel caso di campi di tipo testo o memo.
L'ultimo attributo
riguarda l'eventuale associazione del dato ad un indice, che ne permette la
ricerca random. Per i campi non associati ad indice è possibile solo la ricerca
di tipo sequenziale, che allunga i tempi di risposta del sistema.
L'associazione ad indice complica la struttura del data base, per cui è
necessario valutare campo per campo quali associare ad indice e quali invece
no.
Oltre
all'associazione ad indice, viene definito se il campo può avere valori
ripetuti o no. Questo è fondamentale per l'utilizzo del campo come chiave
primaria di ricerca, ossia come dato in grado di identificare in modo univoco
il record.
Perché un campo
possa essere utilizzato come chiave di ricerca primaria è necessario che sia
associato ad indice e che non siano ammessi duplicati.
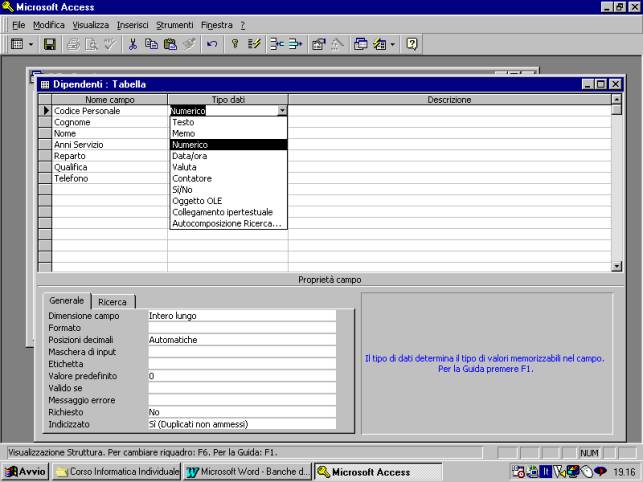
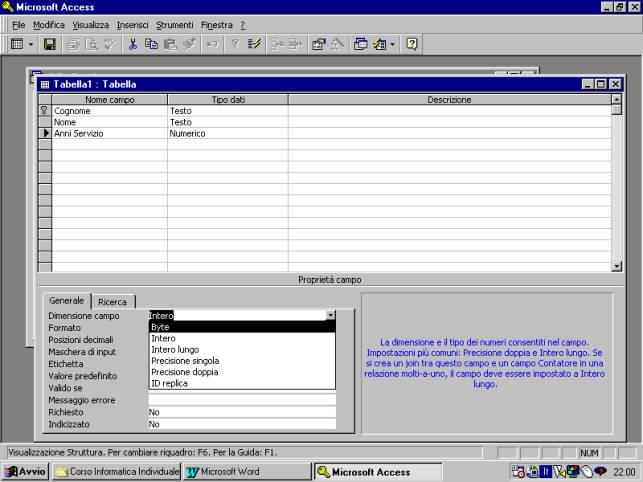
Nella tabella che
segue si ha un esempio di campo numerico.
Viene, inoltre,
impostato come chiave di ricerca primaria il cognome; questo è possibile in
quanto si ipotizza che non possano esserci, nella tabella, cognomi uguali.
Nel caso non sia
possibile utilizzare un solo campo come chiave di ricerca primaria, in quanto
non è garantita la condizione di non duplicazione, la chiave di ricerca
primaria può essere costituita da più campi associati. E' garantita in questo
caso la non duplicazione della coppia di dati.
Nell'esempio che
segue, la chiave di ricerca primaria è data dalla coppia di dati Cognome e
Nome.
Nel caso ciò non
sia possibile, o perché non è esclusa la replicabilità della coppia (o anche di
associazioni di ulteriori altri campi) o perché si preferisce avere una chiave
di ricerca più sintetica, e quindi data da un solo campo, è possibile creare ad
hoc un codice identificativo; nell'esempio questo è dato da un codice
personale, dato aggiunto appositamente per creare un riferimento univoco al
record.
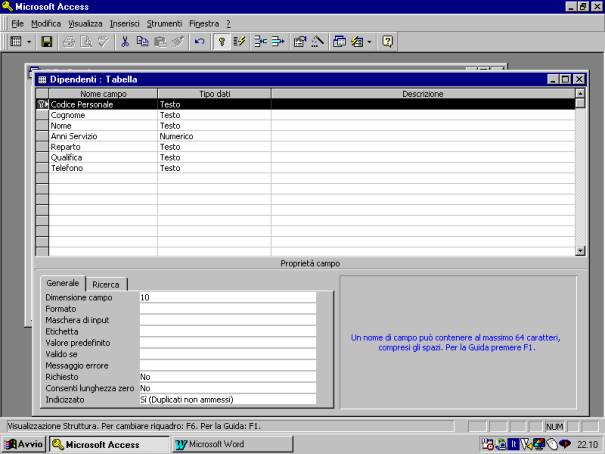
La struttura della
tabella viene completata, con la descrizione di tutti i campi e dei relativi
attributi.
Si noti come
nell'esempio un campo composte esclusivamente di cifre, quale il numero
telefonico, venga definito come testo. Questo è possibile in quanto non si
prevede di utilizzare tale dato in elaborazioni matematiche, ed è opportuno in
quanto si evita di avere delle trasformazioni non richieste del dato originale,
quali ad esempio la soppressione degli zeri non significativi. Inoltre le
possibilità di ricerca associate ad un campo di tipo testo sono più articolate
di quelle possibili con un campo di tipo numerico.
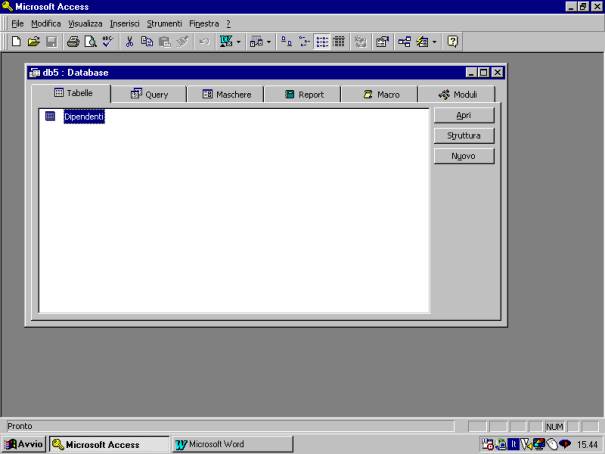
Una volta
completata la struttura, questa può essere inserita in modo definitivo nel data
base, e la tabella potrà essere richiamata per l'inserimento dei dati e per i
successivi aggiornamenti. In questa fase viene assegnato il nome della tabella:
Dipendenti, nel caso utilizzato come esempio.
3.5 Registrazione della tabella.
Al momento
dell'apertura, la tabella si presenta come un modulo, nel quale nelle colonne
sono indicati i campi, ed ogni riga costituisce un record. Al completamento
della registrazione della singola riga, il relativo record viene memorizzato in
modo definitivo nel data base.
Nel caso di
tabelle di grandi dimensioni, lo schermo visualizza una parte della tabella. E'
comunque sempre possibile scorrere la tabella usando i cursori per spostare la
finestra, per visionare ulteriori campi, ed usando i comandi ai piedi della
finestra per visionare altri record.
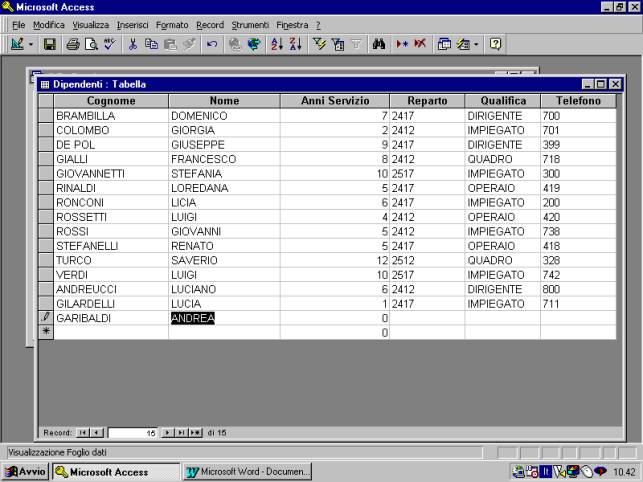
Si noti come, nei
campi costituiti esclusivamente da cifre, sia possibile riconoscere il tipo di
dati dall'allineamento: sulla destra per il tipo numerico (esempio anni di
servizio), sulla sinistra il tipo testo (esempio reparto).
Nella fase di
immissione dei dati, vengono attivate automaticamente le verifiche di
compatibilità, sia quelle legate al tipo dei dati (esempio numerico, data, …)
sia quelle definite dall'utente con l'attributo "valido se ..".
In qualsiasi momento i dati possono essere
modificati e si possono aggiungere nuovi record. Ad ogni riapertura della
tabella i record vengono riordinati in ordine crescente di chiave di ricerca.
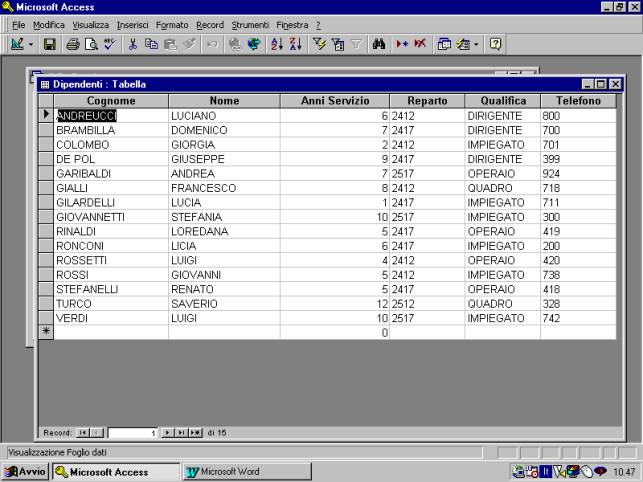
In qualsiasi
momento si può passare dalla tabella dati alla struttura selezionando la
relativa icona, e dalla struttura alla tabella selezionando l'icona foglio
dati.
3.6 L'utilizzo della maschera come interfaccia di
input/output.
L'utilizzo di una
scheda, o maschera, permette di creare un'interfaccia verso la tabella,
dedicando ad esempio l'intera schermata alla rappresentazione di un record.
Questo consente di avere un colloquio più orientato all'utente, i dati possono
essere meglio visualizzati e possono essere inserite ulteriori scritte di
commento.
Per generare una
maschera è sufficiente selezionare la funzione nel menù principale, richiedere
l'autocomposizione, scegliere il tipo di maschera voluto, associare la tabella
che deve essere gestita, selezionare i campi che devono essere inseriti nella
maschera.
Le maschere
generate in autocomposizione possono essere modificate, lavorando
successivamente sulla loro struttura.

3.7 Tabelle correlate.
Regola
fondamentale per i data base è che debbono essere evitate ridondanze inutili
dei dati. Infatti la ripetizione dello stesso dato rappresenta un costo di
gestione, maggiori difficoltà di aggiornamento e possibilità di errore.
Inoltre, tabelle
con un numero elevato di campi sono di più difficile comprensione e gestione,
per cui è sempre preferibile limitare la loro dimensione.
Entrambi i
problemi si risolvono con l'utilizzo di più tabelle messe in relazione tra di
loro.
L'aggancio tra due
tabelle consente di comporre un record logico, del quale fanno parte campi di
record fisici diversi, in quanto appartenenti a tabelle diverse.
La relazione si
attiva nel momento in cui i due campi delle due tabelle, che vengono correlati,
hanno lo stesso contenuto.
Nell'esempio che
segue una tabella libri è correlata ad una tabella utenti, in una applicazione
di gestione prestiti. In figura sono rappresentati i campi ed i dati riferiti a
due record correlati. In grassetto sono indicate le due chiavi di ricerca
primarie. La relazione correla il campo ID Utente di entrambe le tabelle.
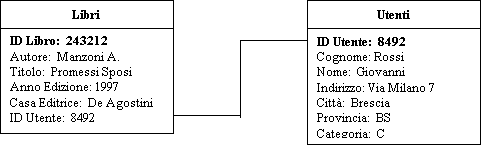
Quando i due campi
hanno lo stesso contenuto, nell'esempio il valore 8492, si crea un record
logico che indica che il libro con ID libro 243212 ed i relativi dati è stato
preso in visione dall'utente identificato dall' ID Utente 8492:
ID Libro: 243212 Autore: Manzoni A. Titolo: Promessi
Sposi Anno Edizione:
1997 Casa Editrice: De Agostini ID Utente: 8492 Cognome: Rossi Nome: Giovanni Indirizzo: Via
Milano 7 Città: Brescia Provincia: BS Categoria: C
In definitiva si dispone del seguente record
logico:
La relazione può
essere tra un record della tabella libri ed un record della tabella utenti se
un utente può prendere in prestito un solo libro, o tra un record della tabella
utenti e più record della tabella libri se un utente può prendere in prestito
più libri. Nel caso in esame non è invece possibile che un libro sia in
prestito a più utenti
In termini
generali, sono possibili tre diversi tipi di relazione:
§
relazione
uno a uno, ad un record di una tabella corrisponde, al massimo, un solo record
di un’altra tabella;
§
relazione
uno a molti, ad un record di una tabella corrispondono più record di un’altra
tabella, non è vero il contrario;
§
relazione
molti a molti, ad un record della prima tabella corrispondono più record della
seconda tabella ed è vero il contrario.
La
relazione uno a uno non è strettamente indispensabile, perché i dati della
seconda tabella potrebbero essere inseriti, senza problemi, nella prima
tabella. Questa relazione può risultare, però, utile, quando devo gestire dati
particolari per un numero limitato di record (ad esempio le persone che hanno un
incarico di lavoro all’estero) o dati che hanno una rilevanza limitata nel
tempo (ad esempio dipendenti con un incarico a tempo negli stand di una fiera).
In ogni caso permette di limitare il numero di campi inseriti in una singola
tabella.
La
relazione uno a molti, invece, come è già stato illustrato nell'esempio
precedente, permette di risolvere i problemi di ridondanza di dati.
Sarebbe
invece necessaria una relazione molti a molti nel caso una stessa circolare
potesse essere in visione presso più utenti ed uno stesso utente potesse avere
in visione più circolari.
La
relazione molti a molti non è gestibile direttamente, ma occorre scinderla in
due relazioni uno a molti, utilizzando una tabella intermedia, nel caso in
esempio la tabella visure.
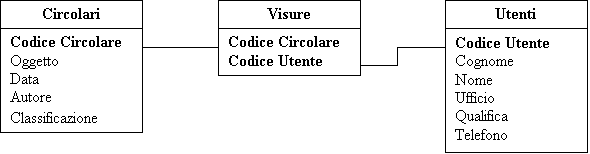
Le
relazioni generate sono del tipo 1 a molti sia tra la tabella circolari e la
tabella visure, che tra la tabella utenti e la tabella visure. Infatti nella
tabelle visure i dati codice circolare e codice utente possono essere ripetuti:
la chiave di ricerca primaria è data dall’accoppiamento dei due dati. Nella
tabella visure possono essere inseriti altri dati quali data della
assegnazione, data di prevista risposta, ecc.
Le
relazioni, che legano tra di loro i dati, devono essere definite dall’utente in
fase di creazione del data base. Il numero di relazioni influenza in modo
esponenziale la complessità della struttura e di conseguenza i tempi di
elaborazione. Ne consegue l’importanza della progettazione della struttura del
data base relazionale per garantire adeguate prestazioni del sistema
informatico.
3.8 Generazione delle relazioni.
La relazione tra
due tabelle viene generata selezionando la relativa funzione nel menù ed
indicando le tabelle su cui operare. La relazione viene generata
automaticamente se i due campi da collegare con la relazione hanno lo stesso
nome. Altrimenti la generazione della relazione viene effettuata trascinando
con il cursore il campo della tabella primaria (valore uno della relazione) sul
campo della tabella secondaria (valore molti della relazione).
Sia la struttura
delle tabelle che la relazione vengono rappresentati in forma grafica.
Nell'esempio alla
tabella dipendenti vista in precedenza viene aggiunta una tabella reparti, che
ha la struttura indicata in figura, e viene creata la relazione tra il campo ID
Reparto della Tabella Reparti ed il campo Reparto della Tabella Dipendenti.
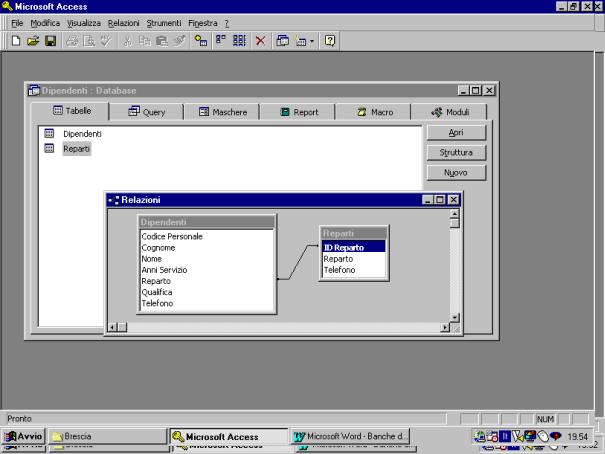
Perché la
relazione possa operare occorre che i dati del campo Reparto della Tabella
Dipendenti trovino corrispondenza nel campo ID Reparto della Tabella Reparti.
3. 9 Estrazione dei dati.
La funzione di
apertura della tabella permette di visualizzare tutti i dati registrati. Nel
caso di tabelle di piccole dimensioni, lo schermo video consente la vista
dell'intero archivio. Quando però l'archivio aumenta di dimensioni è opportuno
poter estrarre soltanto i dati che interessano.
Questo è possibile
mediante la funzione query, che permette di selezionare sia i campi che si
vogliono, sia i record che soddisfano determinate condizioni.
La funzione di
selezione permette inoltre di visualizzare contemporaneamente dati provenienti
da tabelle diverse correlate.
Il risultato di
una query è una tabella, nella quale sono disponibili solo i dati selezionati.
Anche in questo caso è possibile sovrapporre a tale tabella, e quindi alla
query, una maschera che consente di dedicare lo schermo video ad un solo
record, per il quale i dati sono completati da didascalie ed eventuali
commenti.
Le tabelle
generate mediante le query di estrazione dei dati sono di tipo dinamico
(dynaset). In realtà non vengono generate delle nuove tabelle ma semplicemente
vengono creati dei puntatori ai dati presenti nel data base. I dati vengono
trattati quindi in modo dinamico: alla modifica di un dato, vengono modificate
tutte le occorrenze di tale dato.
Quindi i dati
presenti nelle tabelle generate da una query sono modificabili, e le modifiche
effettuate vengono riportate direttamente sul data base.
Per generale le
query si utilizza il linguaggio SQL (Structured Query Language), diventato
ormai uno standard per i linguaggi di interrogazione. Tale linguaggio è
costituito da facili comandi, comprensibili anche per un utente con limitate
competenze informatiche. Invece di usare direttamente il linguaggio SQL, si può
utilizzare una sua interfaccia grafica che semplifica ulteriormente la
creazione del comando di query. Tale interfaccia, di tipo visuale, utilizza la
tecnica Query By Example (QBE); la query viene realizzata compilando una
tabella nella quale vengono selezionati i campi da visualizzare, i criteri di
estrazione, ed eventuali ulteriori operazioni.
In generale, le
fasi di realizzazione di una query prevedono:
§
La selezione della funzione.
§
La scelta di operare mediante la definizione
della struttura della query.
§
La selezione delle tabelle su cui operare.
§
La selezione dei campi su cui operare e dei
campi da inserire nella tabella.
§
La definizione dei criteri di estrazione dei
record.
§
L'esecuzione della query.
Nelle figure
successive vengono riportate alcune delle schermate del processo sino alla
presentazione del modulo di struttura della query.
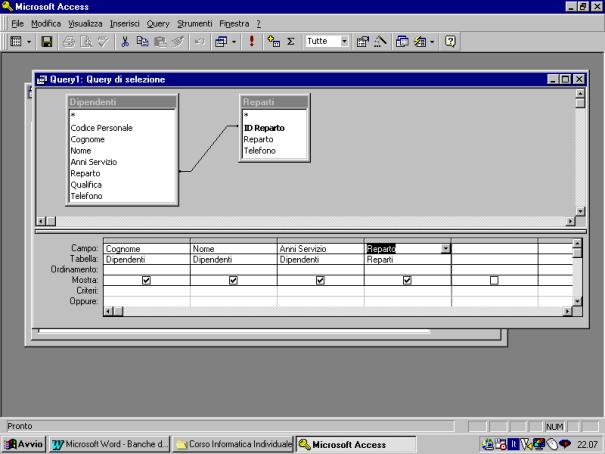
La definizione
della query viene effettuata compilando la griglia della struttura.
I campi vengono
selezionati trasferendoli dalle relative tabelle, mediante trascinamento con il
mouse. Vengono estratti i campi che si desidera visualizzare nella tabella
generata dalla query, selezionati mediante il comando "mostra", ed i
campi che vengono utilizzati per imporre i criteri di estrazione dei record.
Per imporre i
criteri di estrazione vengono utilizzate le righe "criteri" ed
"oppure". Le celle diverse di tali righe sono legate da operatori
AND, se i vincoli sono riportati sulla
stessa riga, e di OR se si trovano su righe diverse.
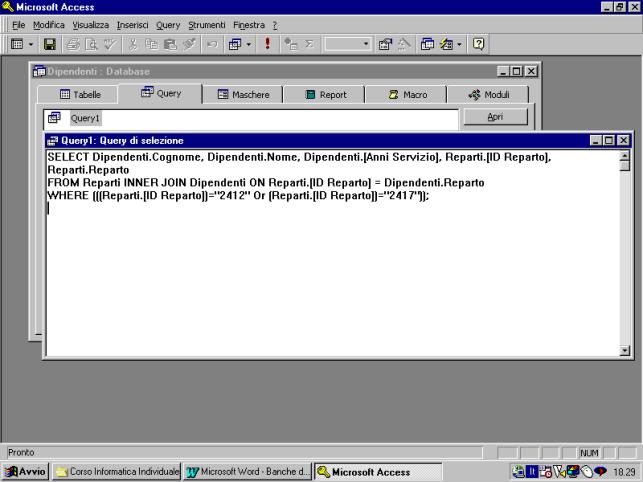
Nell'esempio che
segue si cercano i dipendenti del reparto con codice "2412" con più
di 3 anni di servizio (criterio AND).
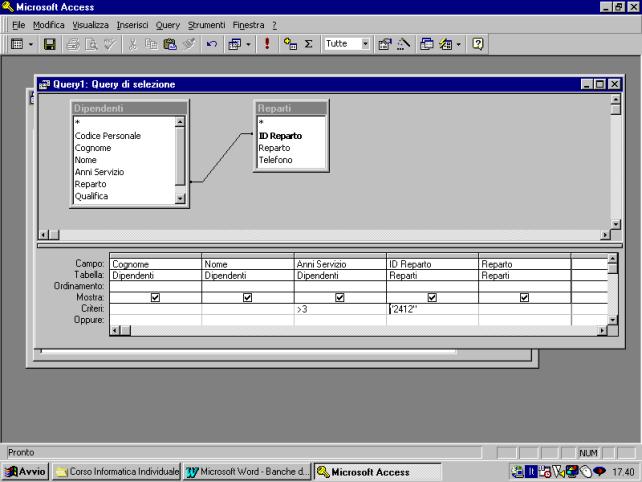
La tabella
generata è quella riportata nella figura che segue.
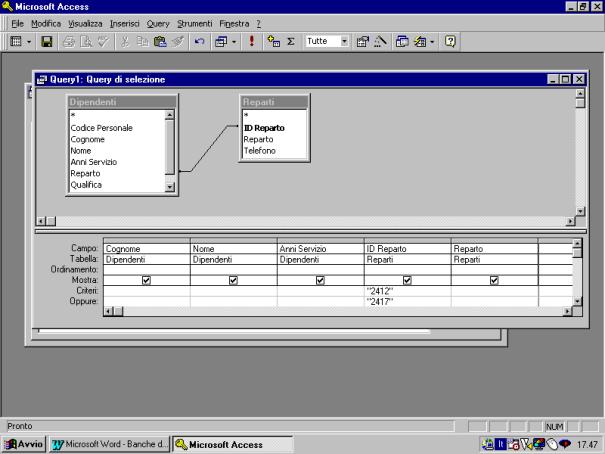
Nella figura
successiva vengono invece selezionati tutti i dipendenti dei reparti con codici
"2412" e "2417". In questo caso viene attivata la relazione
OR, in quanto si selezionando i dipendenti di uno o dell'altro reparto.
Dalla struttura
della query alla sua esecuzione si può passare utilizzando l'icona con il punto
esclamativo o l'icona con il foglio dati, presenti nella barra degli strumenti.
Viceversa per passare dalla tabella generata alla struttura della query si
utilizza il tasto struttura.
La query,
realizzata definendone la struttura, viene quindi tradotta nel corrispondente
comando SQL, che può essere visto scegliendo la relativa modalità nel menù
visualizza.
L'esecuzione della
query avviene per interpretazione del comando SQL.
3.10 Utilizzo dei criteri nelle query di estrazione.
L'utilizzo dei
criteri è fondamentale per estrarre dal data base solo i record voluti.
L'interfaccia QBE permette di operare in vari modi. Nella tabella che segue
sono indicate alcune modalità, le espressioni impostate nella riga criteri, e
il contenuto dei campi selezionati, in funzione del tipo del campo. Per
l'introduzione di dati, le stringhe di caratteri (campo formato testo), vengono
racchiuse tra virgolette, mentre i dati numerici sono rappresentati nella forma
usuale. Introducendo però stringhe di caratteri senza virgolette, nei criteri
di campi definiti come testo, il sistema effettua automaticamente la
conversione al formato corretto.
|
Tipo Criterio |
Criterio |
Tipo Campo |
Contenuto Campo |
|
Identità |
ROSSI "ROSSI" 324 "324" 324 #2/2/99# |
Testo Testo Testo Testo Numerico Data |
Stringa di
caratteri ROSSI Stringa di
caratteri ROSSI Stringa di
caratteri 324 Stringa di
caratteri 324 Valore numerico
324 Data 2/2/99 |
|
Intervallo |
>234,5 >=234,5 >"ROSSI" >#1/1/99# between 3 and 18 between #1/1/99#
and #1/9/99# |
Numerico Numerico Testo Data Numerico Data |
Valore numerico
maggiore di 234,5 Valore maggiore
o uguale a 234,5 Dopo ROSSI in
ordine alfabetico Dopo il giorno
1/1/99 Tra i valori 3 e
18 Tra i giorni
1/1/99 e 1/9/99 |
|
Uso carattere Jolly: ? singolo ·
stringa |
ROSS? ROSS* */*/99 *MO ?ALE ?AL? |
Testo Testo Data Testo Testo Testo |
Stringa ROSS più
un carattere Stringa
qualsiasi che inizia con ROSS Data qualsiasi
del 99 Stringa
qualsiasi che termina con MO Carattere più
stringa ALE Carattere più AL
più carattere |
Utilizzo degli operatori AND e OR..
Le condizioni di
associazione di più criteri, relativi allo stesso dato, possono essere indicate
nella stessa cella con l'utilizzo degli operatori AND e OR.
Ad esempio,
volendo selezionare da una tabella utenti tutti quelli delle provincie di Pavia
e Brescia, nei criteri associati al campo Provincia verrà indicato:
Pavia
or Brescia
Si noti come sia
corretto l'uso dell'operatore OR, in quanto la selezione avviene se la
provincia è Pavia o Brescia. L'operatore AND infatti non permette di
individuare nessun record, in quanto un utente non può essere
contemporaneamente della provincia di Pavia e della provincia di Brescia.
Nel caso si voglia
selezionare, ad esempio, una data di consegna compresa tra il giorno 10
dicembre 1999 ed il giorno 4 gennaio 2000, il criterio può essere formulato con
l'operatore between, come visto nella tavola precedente, o utilizzando gli operatori >,
<,=,AND:
>= #10/12/99# and <= #4/1/00#
Gli operatori AND e OR possono essere ripetuti:
Milano
or Pavia or Brescia
Quando, però, la lista comprende più valori di
estrazione è preferibile utilizzare l'operatore IN:
IN
(Milano; Pavia; Brescia)
Gli operatori NULL
e NOT NULL.
Tale operatore
consente di inserire come criterio la condizione che il campo abbia o no un
valore. Se, ad esempio, nella gestione dei prestiti di una biblioteca voglio
individuare i libri al momento in circolazione, posso selezionare i record nei
quali la data prestito risponde al seguente criterio:
Is
not Null
L'operatore date().
Tale operatore dà
la data del giorno di elaborazione della query, prelevandola dal sistema. Se
pertanto desidero avere una query che seleziona i libri con data prestito
scaduta da più di 60 giorni al momento dell'elaborazione, il criterio associato
a tale campo risulta:
<
date() - 60
Analogamente, se
si vogliono i libri prestati negli ultimi 90 giorni, si userà il seguente
criterio:
Between
date() and date() - 90
Ordinamento
E' possibile
ordinare i dati in un dynaset, scegliendo il tipo di ordinamento (crescente o
decrescente) mediante il corrispondente tasto funzionale nella barra degli
strumenti. Se si scelgono ordinamenti su più campi, i dati vengono ordinati
seguendo la sequenza di come i campi sono presenti nella query, da sinistra a
destra.
3.11 Query con campi calcolati.
Uno dei principi
della banca dati è che non devono essere inseriti nel data base dati che
possono essere ottenuti come elaborazione dei dati presenti. I dati calcolati
possono essere ottenuti inserendo gli opportuni algoritmi nelle query di
selezione.
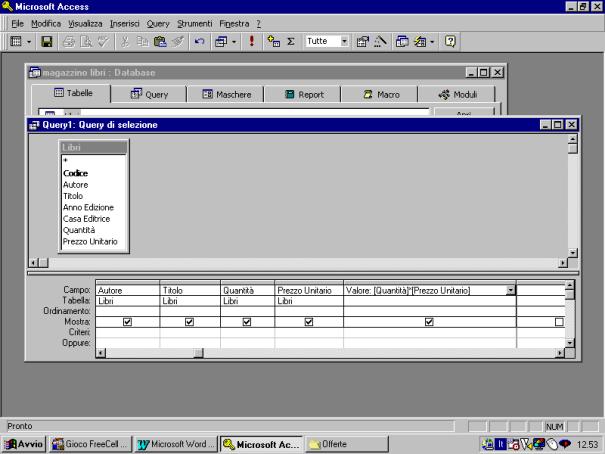
Ad esempio in una
tabella che include i campi Prezzo Unitario e Quantità è possibile calcolare il
campo Valore come prodotto dei due campi.
Sia il nome del
nuovo campo, sia la formula per il calcolo vengono inseriti nella struttura
della query, sulla riga campo.
Nell'esempio che
segue vengono calcolati i valori per tutti i libri presenti in un magazzino. Le
due figure mostrano la struttura della query ed il relativo risultato.
Nella formula i
campi presenti nella tabella vengono indicati tra parentesi quadra.
3.12 Utilizzo delle formule nelle query.
All'interno della
query è possibile raggruppare dati ed eseguire operazioni su campi, operando su
dati caratterizzati dall'appartenenza a record che hanno lo stesso valore nel
campo di raggruppamento.
Tali query vengono
appunto definite di aggregazione.
Le funzioni
disponibili sono:
§
Somma
§
Media
§
Min (minimo)
§
Max (massimo)
§
Conteggio
§
DevSt (deviazione standard)
§
Var (varianza)
§
Primo
§
Ultimo
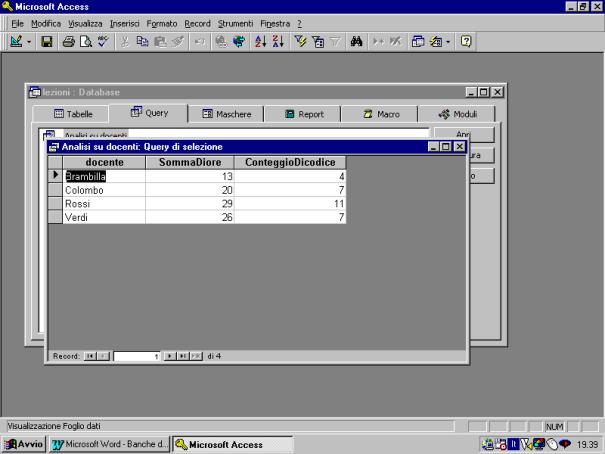
Nell'esempio che
segue, viene creata una tabella che per ogni lezione, indica il docente, il
mese, ed il numero di ore. Viene quindi generata una query che per ogni docente
(su tale campo viene effettuato il raggruppamento) dà il numero di lezioni
impartite (conteggio sul campo codice) ed il totale delle ore (somma sul campo
ore).
Per impostare la
struttura della query viene aggiunta la riga formule, selezionando nel menù
visualizza la funzione formula (o totali) o mediante l'icona sommatoria della
barra degli strumenti.
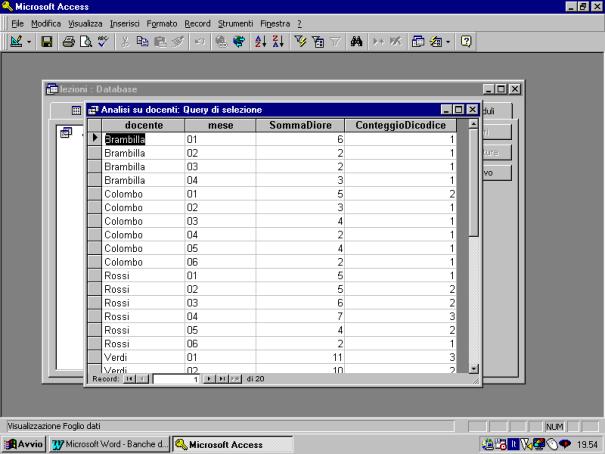
Il raggruppamento
può essere fatto su più gruppi. Nell'esempio successivo vengono forniti gli
stessi dati per docente (primo campo su cui viene effettuato il raggruppamento)
e per mese (secondo campo di raggruppamento).
L'ordine dei
raggruppamenti è dato dalla posizione relativa dei campi, a partire dalla
sinistra della griglia della struttura della query.
Ovviamente è
possibile operare sia sull'intera tabella, sia selezionandone i record mediante
l'utilizzo dei criteri di selezione.
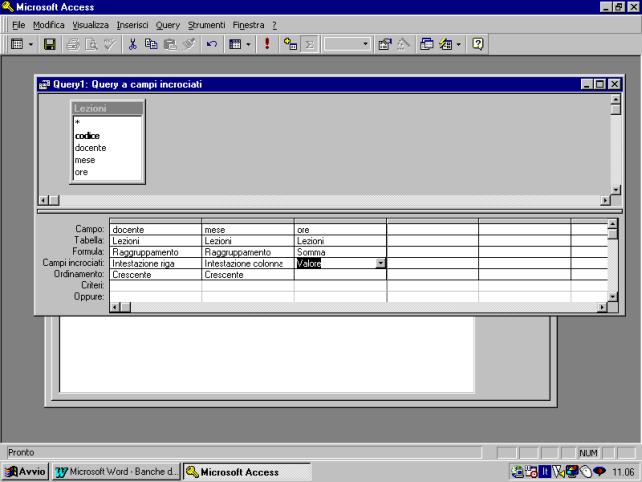
3.13 Query a campi incrociati.
Le tabelle
generate dalle query che utilizzano più campi di raggruppamento presentano
tutti i dati richiesti, ma in una forma poco leggibile. Con le query a campi
incrociati è possibile ottenere le stesse informazioni nella forma di tabella
di riepilogo (tipo foglio elettronico).
Per impostare la
query a campi incrociati, occorre selezionare la relativa funzione nel menù
query, che viene visualizzato quando è attiva la funzione struttura.
La compilazione
della griglia della struttura rispetta le regole già viste. In più occorre
definire quale campo costituisce l'intestazione della riga, e quale campo
l'intestazione della colonna, e quale il valore da inserire nella cella.
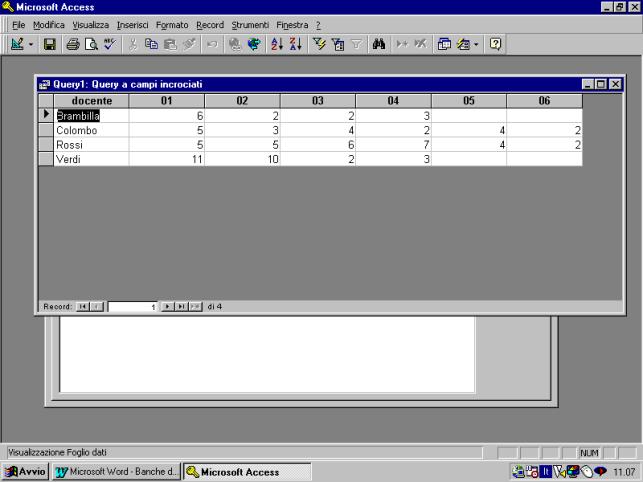
Nell'esempio inoltre i dati docente e mese sono stati ordinati in ordine crescente.
La tabella
generata è riportata nella figura che segue.
3.14 Query parametriche.
Nelle query viste
sino ad ora, tutte le volte che devono essere variati dei parametri occorre
modificare la struttura, il che comporta delle competenze informatiche, anche
se limitate.
Nel caso le
variazioni siano dovute al valore del dato, utilizzato come criterio, e non ai
criteri di impostazione della query, possono essere usate query di tipo
parametrico, nelle quali vengono impostati i criteri nella definizione della
struttura, ma i valori che definiscono il criterio vengono immessi in fase di
esecuzione della query.
In questo caso al
posto del valore viene immessa, nel campo criteri, inserita tra parentesi
quadre, una scritta che verrà evidenziata in fase di esecuzione, associata ad
una finestra di dialogo.
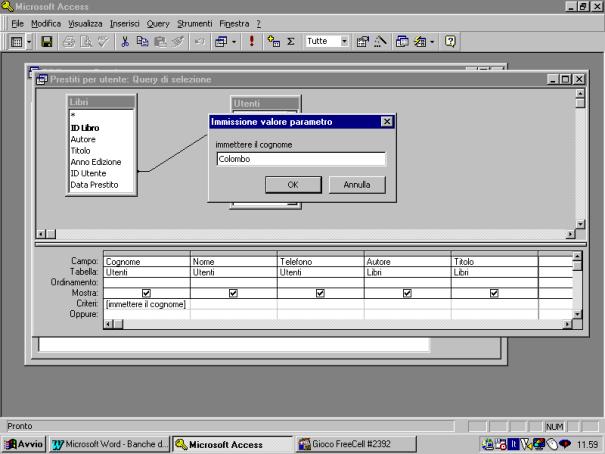
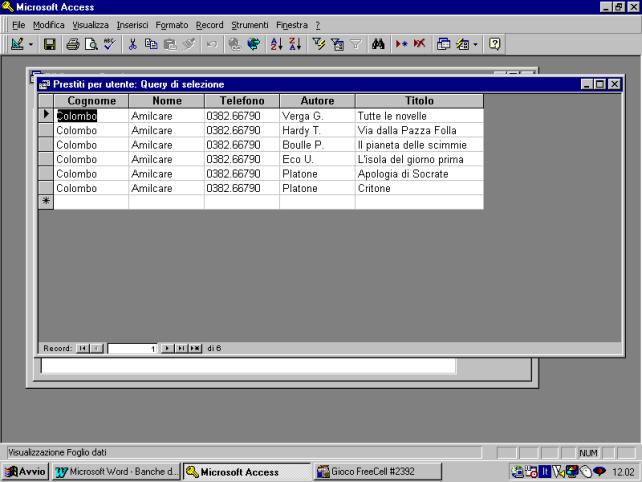
Nell'esempio che
segue, da un data base di gestione di prestiti di una biblioteca si vuole
sapere quali sono i libri presi in prestito da un utente che verrà specificato,
mediante il cognome, al momento della richiesta. Come si può notare nella riga
criteri relativa al cognome viene inserito il comando [immettere il cognome], e
tale scritta compare associata alla richiesta del valore parametro. In fase di
esecuzione vengono richiesti i libri in prestito all'utente con cognome
Colombo.
3.15 Query di comando.
La modifica dei
dati è possibile operando sia direttamente sulle tabelle dei dati sia sulle
tabelle generate dalle query. In questi casi si effettuano modifiche sui
singoli dati.
Con le query di
comando è possibile generare nuove tabelle o portare variazioni sulle tabelle
esistenti, operando contemporaneamente su più record.
Per tali
operazioni sono disponibili quattro tipi di query, selezionabili mediante il
menù query, attivo durante la funzione di definizione della struttura della
query:
§
Creazione tabella
§
Eliminazione
§
Aggiornamento
§
Accodamento
Nelle query di
comando, acquistano significati diversi le due icone della barra degli
strumenti:
§
L'icona con punto esclamativo manda in
esecuzione la query
§
L'icona con la tabella mostra i record ed i
campi sui quali opererà la query in fase di esecuzione.
Creazione Tabella.
La struttura è
identica a quella delle query di selezione. Viene però generata una nuova
tabella permanente. Modifiche apportate ai dati rimangono limitate alla nuova
tabella e non vengono riportate nella tabella originale.
Tale query può
essere utilizzata per creare copie delle tabelle originali, o per fare
selezioni su dati da conservare come documento attestante la situazione di tali
dati ad una certa data.
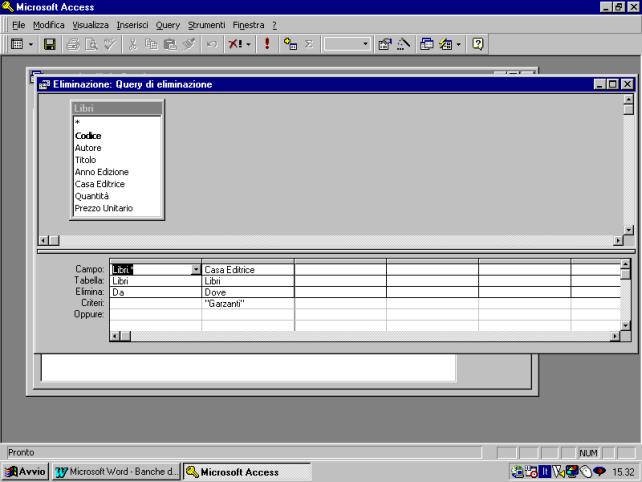
Eliminazione.
Viene utilizzata
per cancellare record da una tabella. Nell'esempio in figura vengono eliminati
dall'archivio tutti i libri della Casa Editrice Garzanti.
Nella griglia
della query vengono selezionati tutti i campi del record, trascinando il
carattere asterisco, posto all'inizio dell'elenco dei campi, nel grafo che
rappresenta la tabella.
In alcuni casi,
l'esecuzione di una query di eliminazione può causare la cancellazione di
record in tabelle correlate.
Accodamento.
E' possibile
accodare ad una tabella record provenienti da un'altra tabella, appartenente
allo stesso o ad altro data base. Le query di accodamento possono essere
utilizzate anche se alcuni campi sono presenti in una sola delle tabelle.
L'utilizzo della
query è guidato da menù di richieste successive.
Se le tabelle
comprendono un campo contatore, questo viene aggiornato automaticamente.
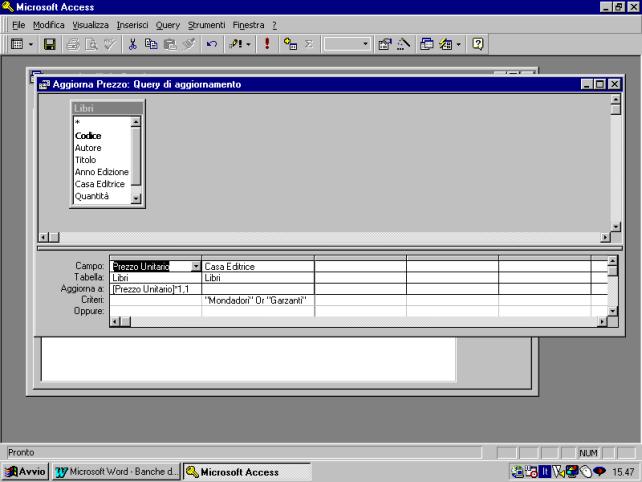
Aggiornamento.
E' possibile
aggiornare dati relativi a tutti i record, che rispecchiano determinate
condizioni.
Nell'esempio
vengono aumentati del 10% i prezzi di tutti i libri delle Case Editrici
Mondadori e Garzanti.
Se si vuole
verificare la funzionalità della query, prima della sua esecuzione, attraverso
il comando selezionato mediante l'icona "foglio dati" della barra
degli strumenti, è possibile vedere i campi che verranno aggiornati, con i
valori precedenti l'aggiornamento.
3.16 I report.
Il report è un
prospetto stampato, nel quale le informazioni sono organizzate in una forma
strutturata scelta dall'utente. Nei report possono essere presenti dati
estratti da tabelle, dati calcolati, scritte, grafici, ecc.
I report possono
essere progettati e realizzati utilizzando maschere di composizione, o si può
ricorrere all'autocomposizione, utilizzando strutture di report predefinite.
Sulla struttura dei report generati in autocomposizione si può intervenire per
introdurre personalizzazioni.
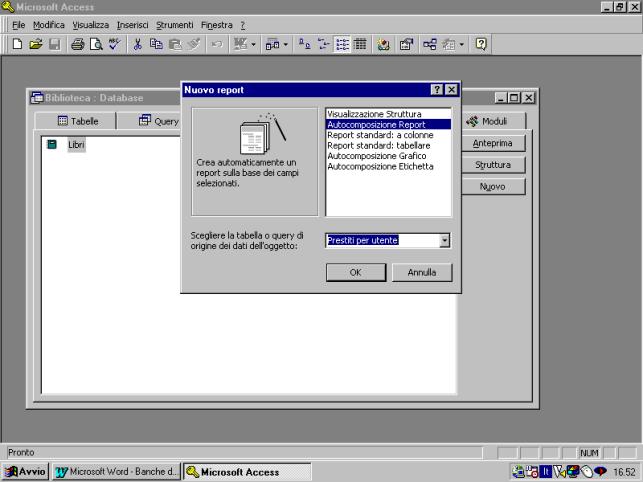
Le forme di report
disponibili in autocomposizione sono riportate nella figura. Come si può
notare, nella finestra di dialogo è inoltre necessario indicare la tabella o la
query da cui il report deve prendere le informazioni.
Una volta
selezionato il tipo di report, devono essere indicati i campi da inserire nel
report. Completate tali operazioni il report può essere visto in anteprima di
stampa o può esserne vista la struttura.
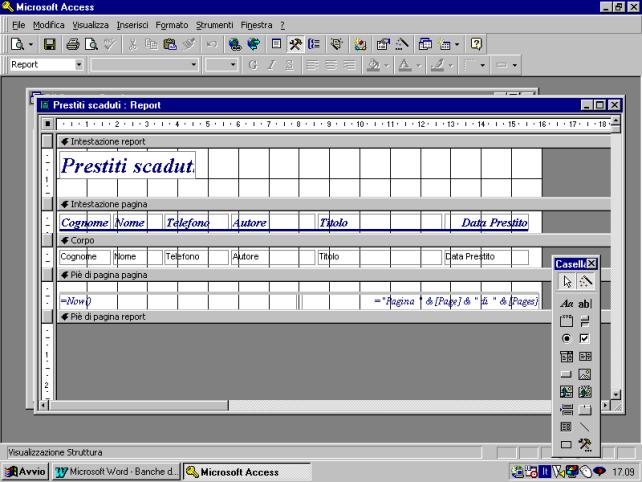
Come si vede nella
struttura vengono inseriti automaticamente:
§
Il nome della tabella, preso dal nome della
query
§
Le intestazioni delle colonne, prese dai
nomi dei campo
§
La data a piè pagina, mediante il comando
=Now()
§
La numerazione della pagina, ed il numero di
pagine totali del report
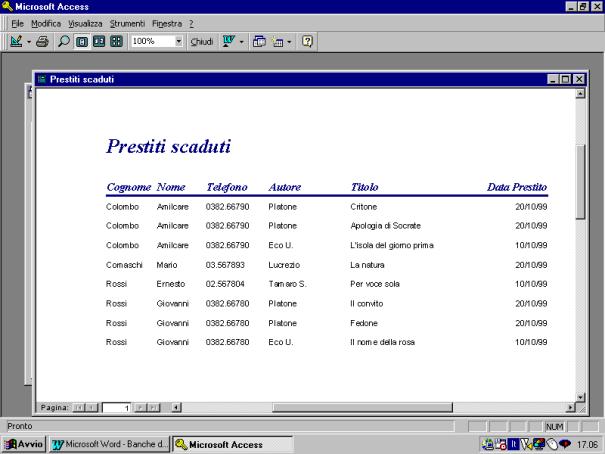
Una copia del
report stampato è riportata alla pagina successiva.